|
1
|
|
|
2
|
- Most random number generators generate a sequence of integers by a
recurrence (linear congruent generator):
- x0 = given
- xn+1 = P1 xn + P2 (mod
N) n=0,1,2,...
- divide by N to get a number in [0,1]
|
|
3
|
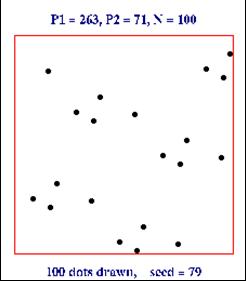
- x0 =79, N = 100, P1 = 263, and P2 = 71
- x1 = 79*263 + 71 (mod 100) = 20848 (mod 100) = 48,
- x2 = 48*263 + 71 (mod 100) = 12695 (mod 100) = 95,
- x3 = 95*263 + 71 (mod 100) = 25056 (mod 100) = 56,
- x4 = 56*263 + 71 (mod 100) = 14799 (mod 100) = 99,
- Subsequent numbers are: 8, 75, 96, 68, 36, 39, 28, 35, 76, 59, 88, 15,
16, 79, 48.
- The sequence then repeats
|
|
4
|
- P1, P2, and N determine the characteristics of the random number
generator
- The choice of x0 (the seed ) determines the particular sequence of
random numbers that is generated.
|
|
5
|
- A sequence is good if it passes several well established statistical
tests.
- Or, it's good if it gives good results in particular applications (where
the meaning of "good results" is heavily dependent upon the
context).
|
|
6
|
- 100 points (xi, xi+1).
- It's clear that there are only 20 points; 100 were drawn, so five lie on
top of each other
- The dots appear to lie along six slanted lines.
- Not very ‘random’
|
|
7
|
- P1 = 16807,
- P2 = 0,
- N= 231 -1 = 2147483647
- Distinctly better
|
|
8
|
- All sequences generated by a linear congruent formula will eventually
enter a cycle which repeats itself endlessly; a good generator will
produce a long sequence of numbers before repeating. The max. length of course is N.
- A linear congruent formula will generate a sequence of maximum length if
and only if the following conditions are met (See Knuth:
- i) P2 is relatively prime to N;
- ii) B = (P1 - 1) is a multiple of p, for every prime p dividing N;
- iii) B = (P1 - 1) is a multiple of 4, if N is a multiple of 4.
|
|
9
|
- The VMS Run-Time Library provides a random number generator routine
called MTH$RANDOM.
- SEED = (69069*SEED + 1) MOD
2**32
- X = SEED/2**32
- Note MTH$RANDOM satisfies the conditions above: i) 1 is relatively prime
to 2**32 since 1 is relatively prime to all numbers.
- ii) 69068 is a multiple of 2, which is the only prime dividing 2**32.
- iii) 69068 is a multiple of 4.
|
|
10
|
- Note for the MTH$RANDOM function if SEED is initially an ODD value then
the new value of SEED will always be an even value. And if SEED is an
EVEN value, then the new value of SEED will be an ODD value. Thus if the
algorithm is repeatedly called, the value of SEED will alternate between
EVEN and ODD values.
|
|
11
|
- More important than starting the MTH$RANDOM generator to get one random
sequence is the problem of restarting the generator to get several
different sequences. You may wish to run a simulation several times and
use a different random sequence each time.
|
|
12
|
- To come up with a good "random" initial SEED value to start
the generator, use the generator itself to produce a random SEED value
to start our random number generator with! Select an initial nonrandom
SEED value, then run the random number generator a few cycles to
generate a random SEED value. We then restart our random number
generator with the new random SEED value, and the output is then a
properly initialized random sequence.
|
|
13
|
- The VMS FORTRAN Run-Time Library contains a random number generator
RANDU, first introduced by IBM IN 1963. This turned out to be a poor
random number generator, but nonetheless it has been widely spread.
- INTEGER*4 SEED
- INTEGER*2 W(2)
- EQUIVALENCE( SEED, W(1) )
- R = FOR$IRAN( W(1), W(2) )
- R is the return value between [0,1). W(1) and W(2) together is the seed
value for the generator. This goes back to the PDP-11 days of 16 bit
integers. SEED is really a 32 bit integer, but it was represented as two
16 bit integers.
|
|
14
|
- SEED = (65539*SEED) MOD 2**31
- X = SEED/2**31
- Note if SEED is initially an odd value, the new SEED generated will also
be an odd value. Similarly, if SEED is initially an even value. Thus
there are at least two disjoint cycles for the RANDU generator.
|
|
15
|
- Actually, the situation is even worse than that.
- For odd SEED values there are two separate disjoint cycles, one
generated by the SEED value 1, and one generated by the SEED value 5.
- The cycles <1> and <5> each contain 536,870,912 values.
Together they account for all of the (2**31)/2 possible odd SEED values.
|
|
16
|
- There are 30 different disjoint cycles using even SEED values.
- TABLE 5.2.2 RANDU WITH EVEN VALUES OF SEED
- CYCLE LENGTH OF CYCLE
- <2> 268435456 <4> 134217728
- <8> 67108864 <10> 268435456
- <16> 33554432 <20> 134217728
- <32> 16777216 <40> 67108864
- <64> 8388608 <80> 33554432
- <128> 4194304 <160> 16777216
- <256> 2097152 <320> 8388608
- <512> 1048576 <640> 4194304
- <1024> 524288 <1280> 2097152
- <2048> 262144 <2560> 1048576
- <4096> 131072 <5120> 524288
- <8192> 65536 <10240> 262144
- <16384> 32768 <20480> 131072
- <32768> 16384 <40960> 65536
- <81920> 32768 <163840> 16384
|
|
17
|
- There are a total of (2**31)/2 = 1,073,741,824 possible even SEED
values; we've accounted for 1,073,709,056 of them. The remaining 32768
SEED values are ones for which the 31 bit binary representation of them
has the lower 16 bits set to 0. These SEED values are treated by RANDU
as if the SEED value were 1, and they result in the cycle <1>.
|
|
18
|
- The 1-D TEST is a frequency test. Imagine a number line stretching from
0 to 1. Use the random number generator to plot random points on this
line. First divide the line into a number of "bins". 1 2 3 4
- |---------|---------|---------|---------|
- 0 .25 .50 .75 1.0
- See how randomly the random number generator fills our bins. If the bins
are filled too unevenly, the Chi-Square test will give a value that's
high, indicating the points do not appear random.
|
|
19
|
- In 2D, divide the plane into squares.
You can think of similar tests in higher dimensions also.
- Define: N = number of trials
- k = number of possible outcomes of the chance experiment
- f(ZETA_i) = number of occurrences of ZETA_i in N trials
- E(ZETA_i) = The expected number
of occurrences of ZETA_i in N trials.
E(ZETA_i) = N*Pr(ZETA_i).
- i=k [ f(ZETA_i) - E(ZETA_i) ]**2
- CHISQ = SUM
-------------------------------------
- i=1 E(ZETA_i)
|
|
20
|
- MTH$RANDOM
- SEED = (69069*SEED + 1) mod 2**32
- X = SEED/2**32 returns real
in range [0,1)
- RATING:
- Fails 1-D above 350,000 bpd (bins per dimension)
- Fails 2-D above 600 bpd
- Fails 3-D above 100 bpd
- Fails 4-D above 27 bpd
- Comments: This generator is also used by the VAX FORTRAN intrinsic
function RAN, and by the VAX BASIC function RND.
|
|
21
|
- RANDU
- SEED = (65539*SEED) mod 2**31
- X = SEED/2**31 returns real in
range [0,1)
- RATING:
- Fails 1-D above 200,000 bpd
- Fails 2-D above 400 bpd
- Fails 3-D above 3 bpd
- Fails 4-D above 6 bpd
- Comments: Note the extremely poor performance for dimensions 3 and
above. This generator is obsolete.
|
|
22
|
- ANSI C ( rand() )
- SEED = (1103515245*SEED + 12345) mod 2**31
- X = SEED returns integer in
range [0, 2**31) RATING:
- Fails 1-D above 500,000 bpd
- Fails 2-D above 600 bpd
- Fails 3-D above 80 bpd
- Fails 4-D above 21 bpd
|
|
23
|
- A simple way to greatly improve any random number generator is to
shuffle the output.
- Start with an array of dimension around 100 (exact size is not
important.)
- Initialize the array by filling it with random numbers from your
generator.
- When the program wants a random number, randomly choose one from the
array and output it to the program.
- Replace the number chosen in the array with a new random number from the
random number generator.
- Note that this shuffling method uses two numbers from the random number
generator for each random number output to the calling program.
|
|
24
|
- ANSI C rand()
- WITHOUT SHUFFLING WITH SHUFFLING
- 1-D Fails above 500,000 bpd Fails above 400,000 bpd
- 2-D Fails above 600 bpd Fails
above 3100 bpd
- 3-D Fails above 80 bpd Fails above 210 bpd
- 4-D Fails above 21 bpd Fails above 55 bpd
|
|
25
|
- The name lfg comes from the Fibonacci sequence 1, 1, 2, 3, 5, 8,
......Xn = Xn-1 + Xn-2.
- LFGs generate random numbers from the following iterative scheme: Xn =
Xn-i + Xn-k (mod m) the lags i and k satisfy the conditions i > k
> 0. i initial values X0, X1,.....,Xi-1 are needed. For most
applications m is power of 2, and with proper choice of i, k, and the
first i values of X, the period is (2i - 1)2(M-1). One problem with LFG
is that i words of memory must be kept current, whereas LCG requires
only that the last value of X be saved.
|
|
26
|
- there should be no inter-processor correlation
- sequences generated on each processor should satisfy the qualities of
serial random number generators
- it should generate same sequence for different number of processors
- it should work for any number of processors
- there should be no data movement between processors
|
|
27
|
- A serial random number sequence is partitioned into non-overlapping
contiguous sections. If there are N processors, and the period of the
serial sequence is P, then the first processor gets the first P/N random
numbers, the second processor gets the second P/N random numbers, etc.
If the user happens to consume more random numbers than expected, then
the sequences could overlap. Another possible problem is that long-range
correlations that exist in serial generators could become short-range
inter-stream or inter-processor correlations in parallel generators
|
|
28
|
- In this approach, the sequence of a serial generator is partitioned in
turn among multiple processors like a deck of cards dealt to card
players. If there are N processors, each processor leapfrogs by N in the
sequence. For example, processor i gets Xi , Xi+N , Xi+2N , etc.
This again has the problem that long-range correlations in the original
sequence can become short-range inter-stream correlations in the
parallel generator.
|
|
29
|
- Both approaches result in non-scalable parallel random number
generators, i.e., the number of different random numbers that can be
used on each processor decreases as the number of processors are
increased.
|
|
30
|
- Parameterization
- The parameterization method is one of the latest methods of generating
parallel random numbers. The exact meaning of parameterization depends
on the type of parallel random number generator. This method identifies
a parameter in the underlying recursion of a serial random number
generator that can be varied. Each valid value of this parameter leads
to a recursion that produces a unique, full-period stream of random
numbers.
|
|
31
|
- Parallelize a lagged Fibonacci generator by running the same sequential
generator on each processor, but with different initial lag tables
- The initialization of the lag tables on each processor is a critical
part of this algorithm. Any correlations within the seed tables or
between different seed tables could have dire consequences.
- Since the initial seeds are chosen at random, there is no guarantee that
the sequences generated on different processors will not overlap.
However using a large lag eliminates this problem to all practical
purposes, since the period of these generators is so long
|
|
32
|
- Scalable Parallel Random Number Generator (SPRNG) is a library
containing several random number generators for serial and parallel
computation, developed jointly by the University of Southern Mississippi
and NCSA. It is callable from Fortran, C, and C++ programs and has been
subjected to some of the largest random number tests (both statistical
and physical). Its speed is also very competitive with the faster
generators.
|
|
33
|
- SPRNG contains the following different random number generators:
- Modified Additive Lagged Fibonacci Generator (lfg)
- Multiplicative Lagged Fibonacci Generator (mlfg)
- 48 bit Linear Congruential Generator (lcg)
- 64 bit Linear Congruential Generator (lcg64)
- Combined Multiple Recursive Generator (cmrg)
- Prime Modulus Linear Congruential Generator (pmlcg) (this one is not
automatically installed)
|
|
34
|
- A hardware (true) random number generator is a piece of electronics that
plugs into a computer and produces genuine random numbers - as opposed
to the pseudo-random numbers that are produced by a computer program. A
typical method is to amplify noise generated by a resistor or a
semi-conductor diode and feed this to a comparator or Schmitt trigger.
If you sample the output (not too quickly) you (hope to) get a series of
bits which are statistically independent. These can be assembled into
bytes, integers or floating point numbers and then, if necessary, into
random numbers from other distributions using methods.
|
|
35
|
- George Marsaglia produced a CD-ROM containing 600 megabytes of random
numbers. These were produced using the best pseudo-random number
generators, but were then combined bytes from a variety of random
sources or semi-random sources (such as rap music).
- Suppose X and Y are independent random bytes (integer values 0 to 255),
and at least one of them is uniformly distributed over the values 0 to
255. Then both the bitwise exclusive-or of X and Y, and X+Y mod 256, are
uniformly distributed over 0 to 255. In addition if both X and Y are
approximately uniformly distributed, then the combination will be more
closely uniformly distributed.
- In the Marsaglia CD-ROM the idea is to get the excellent properties of
the pseudo-random number generator but to break up any remaining
patterns with the random or semi-random generators.
|
|
36
|
- We now have an idea of how to generate a uniform probability
distribution, so that the probability of generating a number between x and
x + dx, denoted p(x)dx, is given by
- p(x)dx = dx 0 < x < 1
- 0 otherwise
- Now suppose that we generate a uniform deviate x and then take some
prescribed
- function of it, y(x). The probability distribution of y, denoted p(y)dy,
is determined
- by the fundamental transformation law of probabilities, which is simply
- |p(y)dy| = |p(x)dx| or p(y) = p(x) dxdy
|
|
37
|
- As an example, suppose that y(x) ≡ −ln(x), and that p(x) is
as given by a uniform deviate. Then
- p(y)dy = |dx/dy| dy = e−y dy
- which is distributed exponentially. This exponential distribution occurs
frequently in real problems, usually as the distribution of waiting
times between independent Poisson-random events, for example the
radioactive decay of nuclei.
|
|
38
|
- Another example is the Box-Muller method for generating random deviates
with a normal (Gaussian) distribution,
- p(y)dy =1/√2π e−y2
/2 dy
|
|
39
|
|
|
40
|
|
|
41
|
|
|
42
|
- Choose a random point in the unit square by finding two random numbers
(x1, x2).
- If this point lies inside the unit circle, consider the choice a ‘hit’,
if not, a ‘miss’.
- Compute the area of a circle by finding the ratio of hits to the total
number of points chosen, N.
- Write an OpenMP code to do this calculation
|
|
43
|
- Does it matter (e.g. timing) whether each thread calculates its own
random sequence or if a master dishes out the random points?
- How does the error scale with N?
|

 Notes
Notes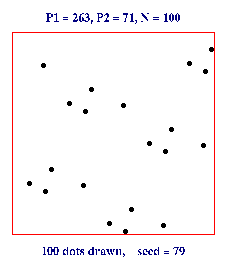{kind=link}
{kind=link}
{kind=link}
{kind=link}
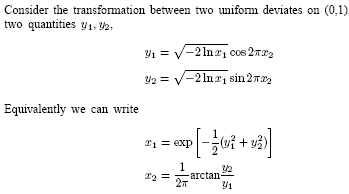{kind=link}
{kind=link}
{kind=link}
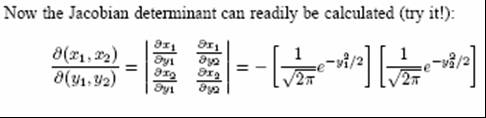{kind=link}