|
1
|
|
|
2
|
- vector-vector a[i]*b[i]
- matrix-vector A[i,j]*b[j]
- matrix-matrix A[I,k]*B[k,j]
|
|
3
|
- for (i=0; i<n; i++)
- for (j=0; j<n; j++)
- {
- C[i,j]=0.0;
- for (k=0; k<n; k++)
- C[i,j]=C[i,j] +
A[i,k]*B[k,j];
- }
- Note:O(n3) work
|
|
4
|
- Serial version - same pseudocode, but interpret i, j as indices of
subblocks, and A*B means block matrix multiplication
- Let n be a power of two, and generate a recursive algorithm. Terminates
with an explicit formula for the elementary 2X2 multiplications. Allows
for parallelism. Can get O(n2.8) work
|
|
5
|
- Pump data left to right and top to bottom
- recv(&A,P[i,j-1]);
- recv(&B,P[i-1,j]);
- C=C+A*B
- send(&A,P[i,j+1]);
- send(&B,P[i+1, j]);
|
|
6
|
|
|
7
|
- Similar method for matrix-vector multiplication. But you lose some of
the cache reuse
|
|
8
|
|
|
9
|
|
|
10
|
- Simple do loops not effective
- Cache and memory hierarchy bottlenecks
- For better performance,
- combine loops
- minimize memory transfer
|
|
11
|
- library of subroutines to solve linear algebra
- example – LU decomposition and system solve (dgefa and dgesl, resp.)
- In turn, built on BLAS
- see netlib.org
|
|
12
|
- a library of subroutines designed to provide efficient computation of
commonly-used linear algebra routines, like dot products, matrix-vector
multiplies, and matrix-matrix multiplies.
- The naming convention is not unlike other libraries - the fist letter
indicates precision, the rest gives a hint (maybe) of what the routine
does, e.g. SAXPY, DGEMM.
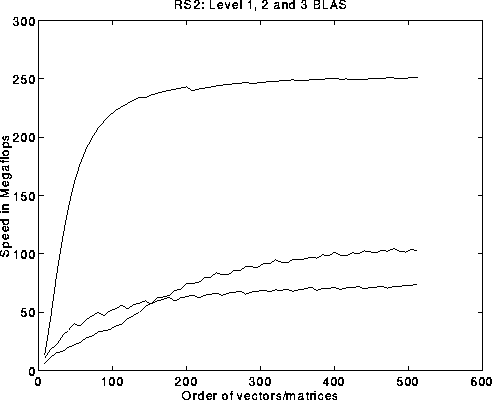
- The BLAS are divided into 3 levels: vector-vector, matrix-vector, and
matrix-matrix. The biggest speed-up usually in level 3.
|
|
13
|
|
|
14
|
|
|
15
|
|
|
16
|
- load/store float ops refs/ops
- level 1
- SAXPY 3N 2N 3/2
- level 2
- SGEMV MN+N+2M 2MN 1/2
- level 3
- SGEMM 2MN+MK+KN 2MNK 2/N
|
|
17
|
- read x(1:n) into fast memory
- read y(1:n) into fast memory
- for i = 1:n
- read row i of A into fast
memory
- for j = 1:n
- y(i) = y(i) + A(i,j)*x(j)
- write y(1:n) back to slow memory
|
|
18
|
- m=# slow memory refs = n^2 +3n
- f=# arithmetic ops = 2n^2
- q=f/m ~2
- Mat-vec multiple limited by slow memory
|
|
19
|
|
|
20
|
- for i = 1 to n
- read row i of A into fast memory
- for j = 1 to n
- read C(i,j) into fast
memory
- read column j of B into
fast memory
- for k = 1 to n
- C(i,j) = C(i,j) +
A(i,k) * B(k,j)
- write C(i,j) back to slow
memory
|
|
21
|
- Number of slow memory references on unblocked matrix multiply
- m = n^3 read each column of B n times
- + n^2 read each column of A once for each
i
- + 2*n^2 read and write
each element of C once
- = n^3 + 3*n^2
- So q = f/m = (2*n^3)/(n^3 + 3*n^2)
- ~= 2 for large n, no
improvement over matrix-vector multiply
|
|
22
|
- Consider A,B,C to be N by N matrices of b by b subblocks where b=n/N is
called the blocksize
- for i = 1 to N
- for j = 1 to N
- read block C(i,j) into
fast memory
- for k = 1 to N
- read block A(i,k) into fast
memory
- read block B(k,j) into fast
memory
- C(i,j) = C(i,j) + A(i,k) *
B(k,j) {do a matrix multiply on blocks}
- write block C(i,j) back to
slow memory
|
|
23
|
- Number of slow memory references on blocked matrix multiply
- m = N*n^2 read each block of B N^3 times (N^3 * n/N * n/N)
- + N*n^2 read each block of A N^3 times
- + 2*n^2 read and write each block of C
- = (2*N + 2)*n^2
- So q = f/m = 2*n^3 / ((2*N + 2)*n^2)
- ~= n/N = b for large n
|
|
24
|
- So we can improve performance by increasing the blocksize b
- Can be much faster than matrix-vector multiplty (q=2)
- Limit: All three blocks from
A,B,C must fit in fast memory (cache), so we
- cannot make these blocks
arbitrarily large: 3*b^2 <= M, so q ~= b <= sqrt(M/3)
|
|
25
|
- Industry standard interface(evolving)
- Vendors, others supply optimized implementations
- History
- BLAS1 (1970s):
- vector operations: dot product, saxpy
- m=2*n, f=2*n, q ~1 or less
- BLAS2 (mid 1980s)
- matrix-vector operations
- m=n^2, f=2*n^2, q~2, less overhead
- somewhat faster than BLAS1
|
|
26
|
- BLAS3 (late 1980s)
- matrix-matrix operations: matrix matrix multiply, etc
- m >= 4n^2, f=O(n^3), so q can possibly be as large as n, so BLAS3
is potentially much faster than BLAS2
- Good algorithms used BLAS3 when possible (LAPACK)
- www.netlib.org/blas, www.netlib.org/lapack
|
|
27
|
|

 Notes
Notes{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}