|
1
|
|
|
2
|
|
|
3
|
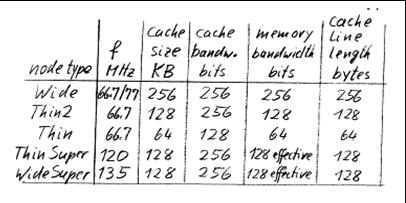
- Different versions -- with different frequency, cache size and bandwidth
|
|
4
|
|
|
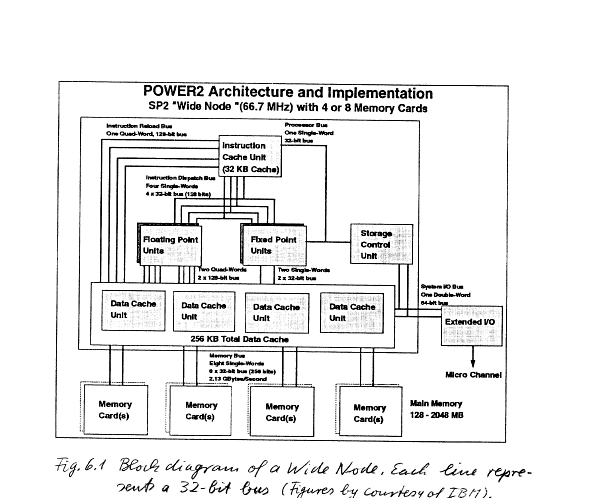
5
|
- Double fixed point/floating point units -- multiply/add in each
- Max. 4 Floating Point results/cycle
- ICU (with 32 KB instruction cache) can execute a branch and a
condition/cycle
- Per cycle 8 instructions may be issued and executed -- truly SUPERSCALAR!
|
|
6
|
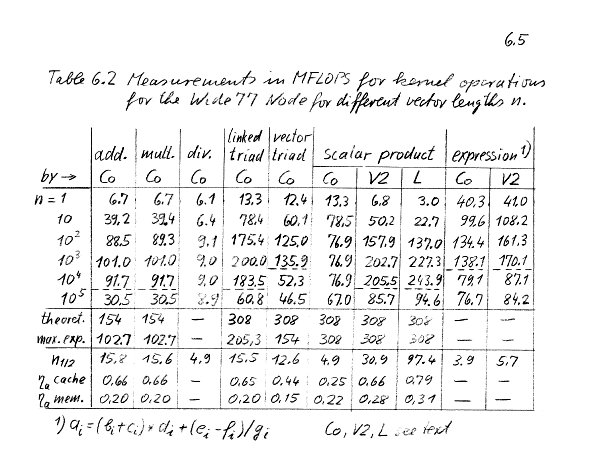
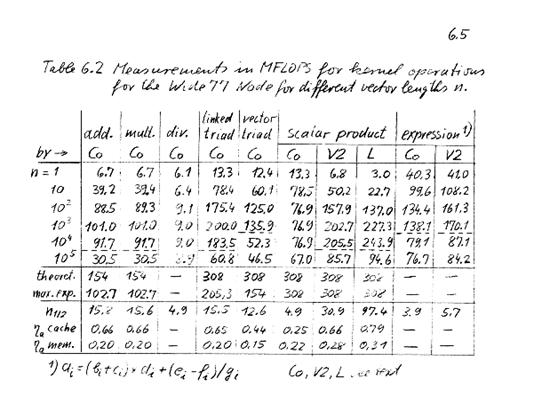
- Theoretical peak performance:
- 2*77 = 154 MFLOP for dyad
- 4*77 = 308 MFLOP for triad
- Cache Effects dominate performance
- 256 KB Cache and 256 bit path to cache and from cache to memory -- 2
words (8 bytes each) may be fetched and 2 words stored per cycle
|
|
7
|
- Expected Performance
- For Dyad ai= bi*ci or ai=bi+ci -- needs 2 load and 1 store i.e. 6
memory references to feed 2 FPUs -- only 4 are available:
- (2*77)*(4/6) = 102.7 MFLOP
- For linked triad
- ai= bi + s*ci (2 load 1 store)
- (4*77)*(4/6) = 205.3 MFLOP
- For vector triad
- ai = bi + ci * di (3 load
1 store)
- (4*77)*(4/8)=154 MFLOPS
|
|
8
|
- The Performance numbers assumed that data was available in cache
- If data is not in cache it must be fetched in cache lines of 256 bytes
each from memory at a much slower pace
|
|
9
|
|
|
10
|
- Based on the analysis of the Power 2 processor and IBM SP presented here
prepare a similar analysis (including estimates of performance) for the
new NEC SX chips of the Earth Simulator, or the Power 4 chips.
|

 Notes
Notes{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}