|
1
|
|
|
2
|
- Speedup = (time for 1 processor)/(time for p processors)
- Shouldn’t include wait time, I/O
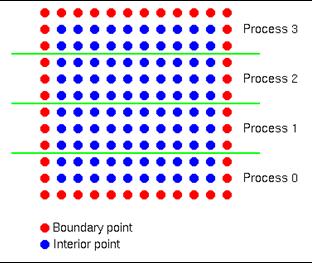
- Self-scheduling – master/slave relationship. Good when slaves do not to communicate
among themselves.
|
|
3
|
|
|
4
|
|
|
5
|
|
|
6
|
- matrix-vector multiply A*b = c
- each row of A in turn multiplied by b; reassemble product vector
- master sends b to all processors
- master sends one row at a time to each slave
- slaves send the ‘dot products’ back to master, with tag identifier
|
|
7
|
|
|
8
|
|
|
9
|
|
|
10
|
|
|
11
|
|
|
12
|
- To compute c, require n multiplies, n-1 adds, for each row, so total
work is n*(n+[n-1]) = 2*n2 –n
- Total time of computation is
- (2*n2 –n)*Tcomp
|
|
13
|
- Ignore communication of b (assume its there aready)
- Ignore effect of message size on communication
- To communicate, require n sends (rows of A) + 1 for the answer back, for
each row, so total communication is n*(n+1) = n2 +n
- Total time of communication is
- (n2 +n)*Tcomm
|
|
14
|
- Ratio is
- [(n2 +n)*Tcomm
] / [(2n2 -n)*Tcomp ]
- Tcomm >> Tcomp
- Would like ratio to decrease with n, but here it asymptotes to ½
- Means communication always a bottleneck
|
|
15
|
- Assume B distributed to all slaves
- Dot product of columns of B with rows of A
- To compute C, require n multiplies, n-1 adds, for each element of A, so
total work is n2 *(n+[n-1]) = 2*n3 –n2
|
|
16
|
- Again, ignore effect of message size on communication
- To communicate, require n sends (rows of A) + n for the answer row, for
each row, so total communication is n*(2n)
|
|
17
|
- Ratio is
- [(2n2 )*Tcomm
] / [(2n3 -n2)*Tcomp ]
- Tcomm >> Tcomp
- Asymptotes to 1/n
- Relatively better performance for large n
|
|
18
|
- ‘Instrumenting’ the code
- MPE library
- Create logfiles, describe states and events
- upshot output is graphical display; could display raw numbers
- show, e.g., time in send, recv, compute, Bcast
|
|
19
|
- int MPI_Bcast( void *buf, int count,MPI_Datatype datatype, int root,
MPI_Comm comm )
- {
- int result;
- MPE_Log_event( S_BCAST_EVENT, Bcast_ncalls, (char *)0 );
- result = PMPI_Bcast( buf, count, datatype, root, comm );
- MPE_Log_event( E_BCAST_EVENT, Bcast_ncalls, (char *)0 );
- return result;
- }
|
|
20
|
- MPI_Init">int MPI_Init( int *argc, char ***argv )
- {
- int procid, returnVal;
- returnVal = PMPI_Init( argc, argv );
- MPE_Initlog();
- MPI_Comm_rank( MPI_COMM_WORLD, &procid );
- if (procid == 0)
- { MPE_Describe_state(
S_SEND_EVENT, E_SEND_EVENT,
- "Send",
"blue:gray3" );
- MPE_Describe_state(
S_RECV_EVENT, E_RECV_EVENT,
- "Recv",
"green:light_gray" );
- ...
- }
- return returnVal;
- }
|
|
21
|
- ∆u = f on unit square 0
< x, y < 1
- u = g on boundary
- define grid points xi yj i, j = 0,…n+1
- set h=1/(n+1)
|
|
22
|
- uk+1ij = (1/4)*(uki-1j + uki+1j + ukij-1 + ukij+1-
h2 fij )
|
|
23
|
|
|
24
|
|
|
25
|
|
|
26
|
- integer dims(2)
- logical isperiodic(2), reorder
- dims(1)=3
- dims(2)=3
- isperiodic(1)=.false.
- isperiodic(2)=.false.
- reorder=.true.
- ndim=2
- call MPI_CART_CREATE(MPI_COMM_WORLD, ndim, dims, isperiodic, reorder,
comm2d, ierr)
|
|
27
|
- find neighbors
- call MPI_CART_GET(comm2d, 2, dims, isperiodic, coords, ierr)
- myrank in comm2d
- call MPI_COMM_RANK(comm2d, myrank, ierr)
- get coordinates of a process
- call MPI_CART_COORDS(comm2d, myrank, 2, coords, ierr)
- find destination and source of shifting
- call MPI_CART_SHIFT(comm1d, 0, 1, nbrottom, nbrtop, ierr)
|
|
28
|
- c This routine show how to determine the neighbors in
- c a 2-d decomposition of the
domain.
- c Assumes that MPI_Cart_create has already been called
- subroutine fnd2dnbrs( comm2d, $ nbrleft, nbrright, nbrtop,
- & nbrbottom )
- integer comm2d, nbrleft, nbrright, nbrtop, nbrbottom
- integer ierr
- call MPI_Cart_shift( comm2d, 0, 1, nbrleft, nbrright, ierr )
- call MPI_Cart_shift( comm2d, 1, 1, nbrbottom, nbrtop, ierr )
- return
- end
|
|
29
|
- subroutine fnd2ddecomp( comm2d, n, sx, ex, sy, ey )
- integer comm2d
- integer n, sx, ex, sy, ey
- integer dims(2), coords(2), ierr
- logical periods(2)
- call MPI_Cart_get( comm2d, 2, dims, periods, coords, ierr )
- call MPE_DECOMP1D( n, dims(1), coords(1), sx, ex )
- call MPE_DECOMP1D( n, dims(2), coords(2), sy, ey )
- return
- end
|

 Notes
Notes{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}