|
1
|
|
|
2
|
- To send k bytes
- tcomm(k) = tstartup+ (h-1)tstart-hop+(k+k0)tsend+tblock
- tstartup: Total time in setting up the communication
- tstart-hop :Time for
switching each “hop” in wormhole routing
- h: no. of hops k: no. of
bytes to transfer
- k0 : extra header bytes that are also moved
- tsend :time to actually transfer k byte
- tblock : time used in blocked messages en route
|
|
3
|
- Speed = k/tcomm
- Actual << Theoretical hardware limit advertised
- Consequences
- Send messages in blocks -- avoid small single messages
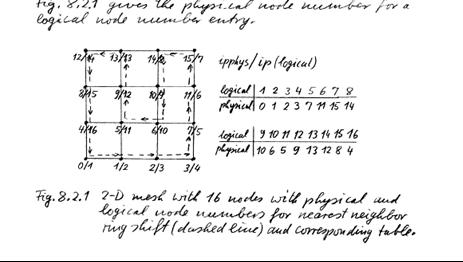
- Arrange data distributions to get nearest neighbor communications e.g.
use ring shift with direct neighbors
|
|
4
|
- Program with logical processor numbers
|
|
5
|
- Latency Hiding: use asynchronous messaging to overlap communication and
computation (MPI_ISEND,MPI_IRECV)
- Domain decomposition in solving grid problems; Compute with first and communicate those while
computing
|
|
6
|
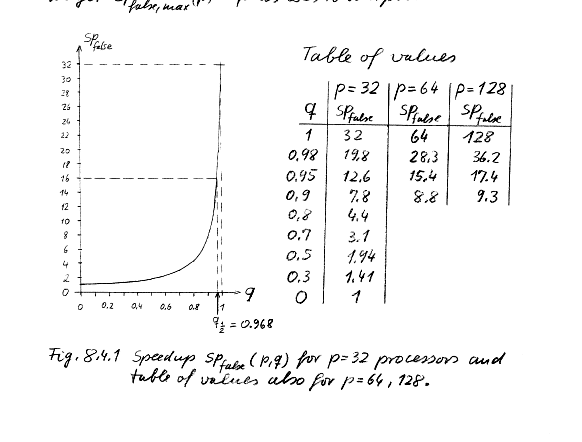
- Consider the execution of a program on p processors - let the part q
(0<q<1) of each operation be parallelized. Maximum speedup
- spfalse = tk/tp = k/ [(q/p) +(1-q)]
- Indicates the rapid loss of speedup if parallel fraction is not high
enough as p increases
- To get 50% efficiency i.e. 256 on 512 q =0.998
|
|
7
|
|
|
8
|
- Why False in speedup ?
- Assumed that no. of ops are same for sequential and parallel -- usually
algorithms and data structures are different
- Did not account for parallelization cost -- communication and
synchronization costs!
- assumed that performance does not change for sequential/parallel code
(diff. vector length ...)
|
|
9
|
- sphon= t1 for best sequential algorithm, tp
for real parallel algoithm
- = [t1..]/[...+hbas +php]
(complex form -diff to use)
- hp : communication time that depends on p
|
|
10
|
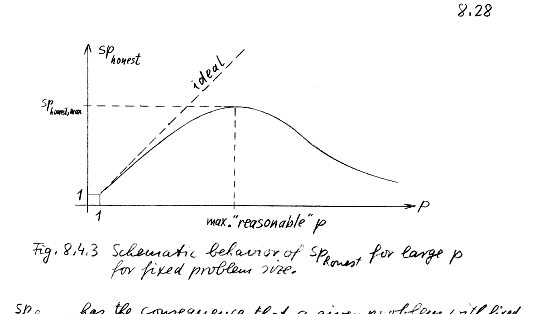
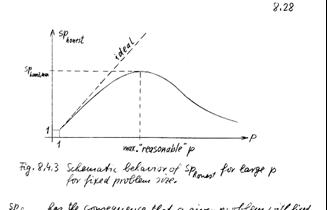
- There is an optimal number of processors for each problem
- Fixed problem size with increasing numbers of processors is a poor use
of parallel machine
|
|
11
|
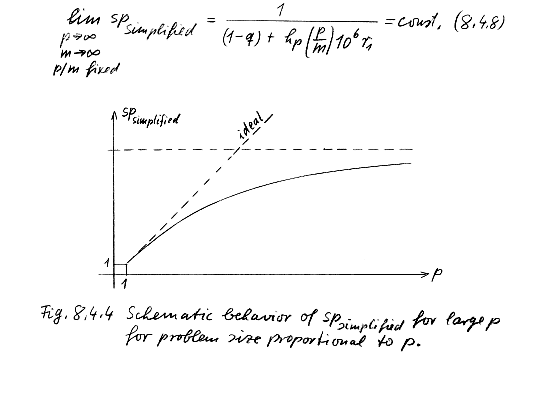
- Increasing problem size with increasing numbers of processors leads to
better use of parallel machine
|
|
12
|
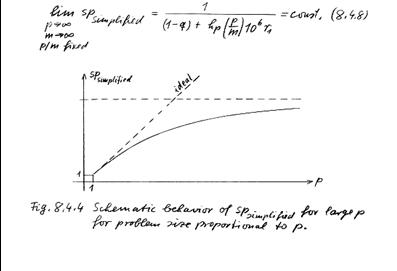
- Now let problem size m-->infty as p -->infty
|
|
13
|
- Thus scalability is the desired measure of a parallel algorithm/code and
not speedup!
- Scalability is achieved if the quantity
- [hp*p/m] is constant or increases very slowly as p
increases
|

 Notes
Notes{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
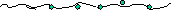{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
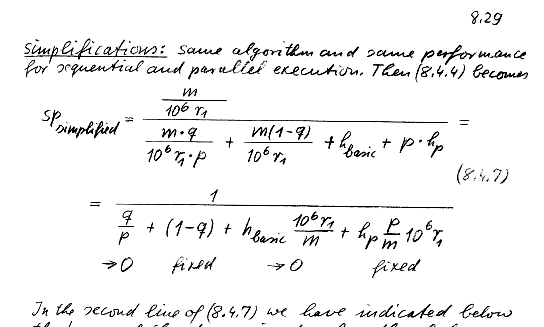{kind=link}
{kind=link}
{kind=link}
{kind=link}